from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
from sqlalchemy import String, Integer, DateTime,Index,Text,ForeignKey
from datetime import datetime
from typing import Optional
class Base(DeclarativeBase):
pass
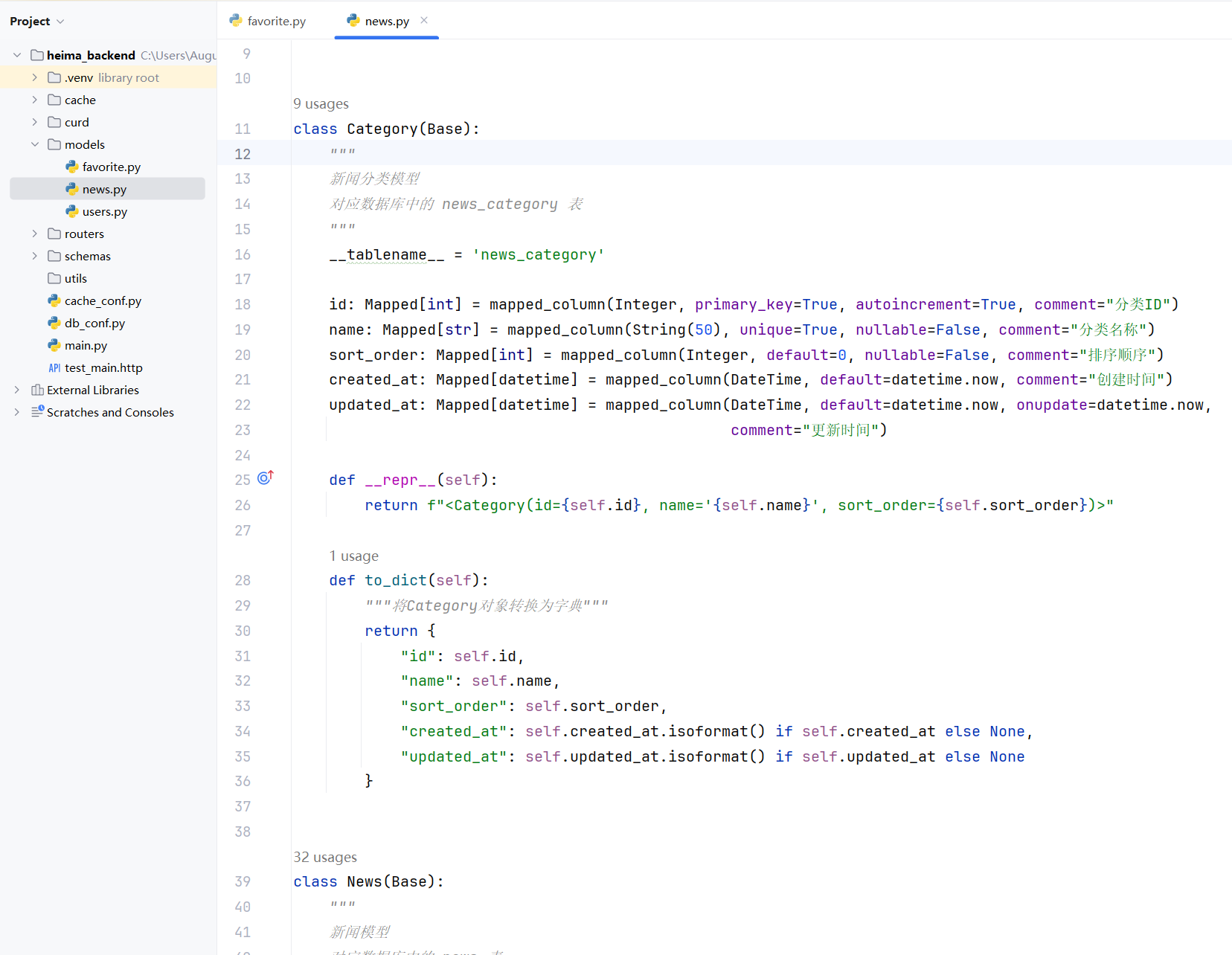
class Category(Base):
"""
新闻分类模型
对应数据库中的 news_category 表
"""
__tablename__ = 'news_category'
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True, comment="分类ID")
name: Mapped[str] = mapped_column(String(50), unique=True, nullable=False, comment="分类名称")
sort_order: Mapped[int] = mapped_column(Integer, default=0, nullable=False, comment="排序顺序")
created_at: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, comment="创建时间")
updated_at: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, onupdate=datetime.now,
comment="更新时间")
def __repr__(self):
return f"<Category(id={self.id}, name='{self.name}', sort_order={self.sort_order})>"
def to_dict(self):
"""将Category对象转换为字典"""
return {
"id": self.id,
"name": self.name,
"sort_order": self.sort_order,
"created_at": self.created_at.isoformat() if self.created_at else None,
"updated_at": self.updated_at.isoformat() if self.updated_at else None
}
class News(Base):
"""
新闻模型
对应数据库中的 news 表
"""
__tablename__ = 'news'
# 创建索引
__table_args__ = (
Index('fk_news_category_idx', 'category_id'),
Index('idx_publish_time', 'publish_time'),
)
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True, comment="新闻ID")
title: Mapped[str] = mapped_column(String(255), nullable=False, comment="新闻标题")
description: Mapped[Optional[str]] = mapped_column(String(500), comment="新闻简介")
content: Mapped[str] = mapped_column(Text, nullable=False, comment="新闻内容")
image: Mapped[Optional[str]] = mapped_column(String(255), comment="封面图片URL")
author: Mapped[Optional[str]] = mapped_column(String(50), comment="作者")
category_id: Mapped[int] = mapped_column(Integer, ForeignKey('news_category.id'), nullable=False, comment="分类ID")
views: Mapped[int] = mapped_column(Integer, default=0, nullable=False, comment="浏览量")
publish_time: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, comment="发布时间")
created_at: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, comment="创建时间")
updated_at: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, onupdate=datetime.now,
comment="更新时间")
def __repr__(self):
return f"<News(id={self.id}, title='{self.title}', views={self.views})>"
def to_dict(self):
"""将News对象转换为字典"""
return {
"id": self.id,
"title": self.title,
"description": self.description,
"content": self.content,
"image": self.image,
"author": self.author,
"category_id": self.category_id,
"views": self.views,
"publish_time": self.publish_time.isoformat() if self.publish_time else None,
"created_at": self.created_at.isoformat() if self.created_at else None,
"updated_at": self.updated_at.isoformat() if self.updated_at else None
}