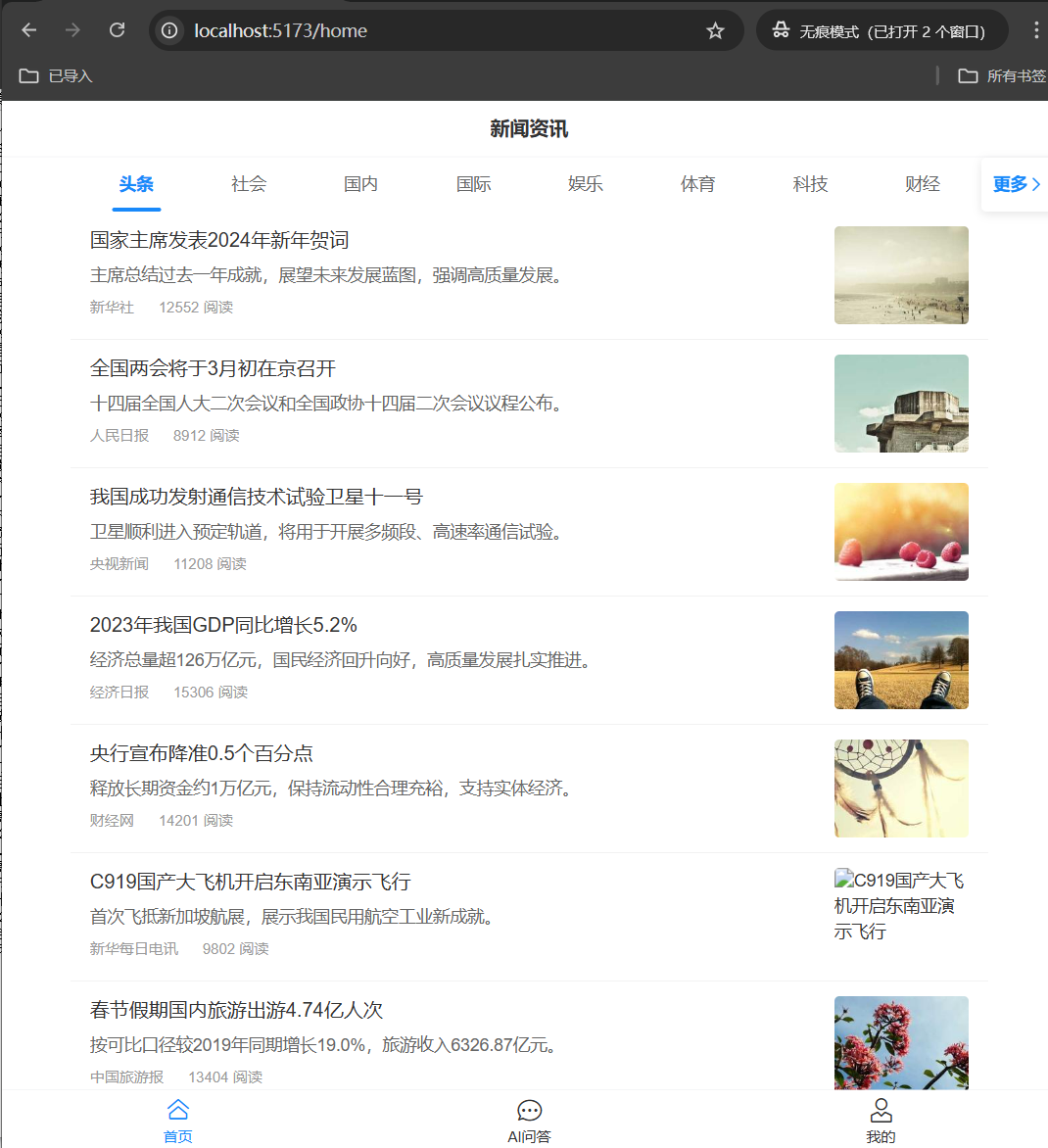
新闻列表
获取新闻列表
I.请求与响应过程
当用户访问首页时,首先需要从从后端获取新闻数据,然后前端通过js代码将获取的数据加载到页面中
flowchart LR
subgraph B [后端]
U[FastAPI服务]
end
subgraph A [首页界面]
direction LR
F1[新闻分类]
F2[新闻列表]
end
A -- ① 请求分类<br> /api/news/list --> B
B -- ② 返回响应 <br> {code: 200,message: success,data: [{id: 1,title: 新闻标题,description: 新闻简介,image: 图片URL,author: 作者,publishTime: 发布时间,categoryId: 1,views: 1000}]} --> A
II. 路由定义
在news.py文件,编写路由解析代码
| ## ...............
## 其他代码
## ...............
@router.get("/list")
async def read_news(category_id: int = Query(..., alias="categoryId"), page: int = Query(default=1),page_size: int = Query(default=10, alias="pageSize", le=100),db: AsyncSession = Depends(get_db)):
"""
获取新闻列表接口(支持分页和分类筛选)
Args:
category_id (int): 分类ID,必填参数,通过查询参数categoryId传入
page (int, optional): 页码,从1开始,默认为第1页
page_size (int, optional): 每页显示的新闻数量,最大值为100,默认为10
db (AsyncSession): 通过依赖注入获取的数据库会话对象
Example:
GET /api/news/list?categoryId=1
GET /api/news/list?categoryId=1&page=2&pageSize=20
"""
return {
"code": 200,
"message": "success",
"data": "列表数据"
}
|

在main.py文件中已经对路由文件进行过注册,无需再操作
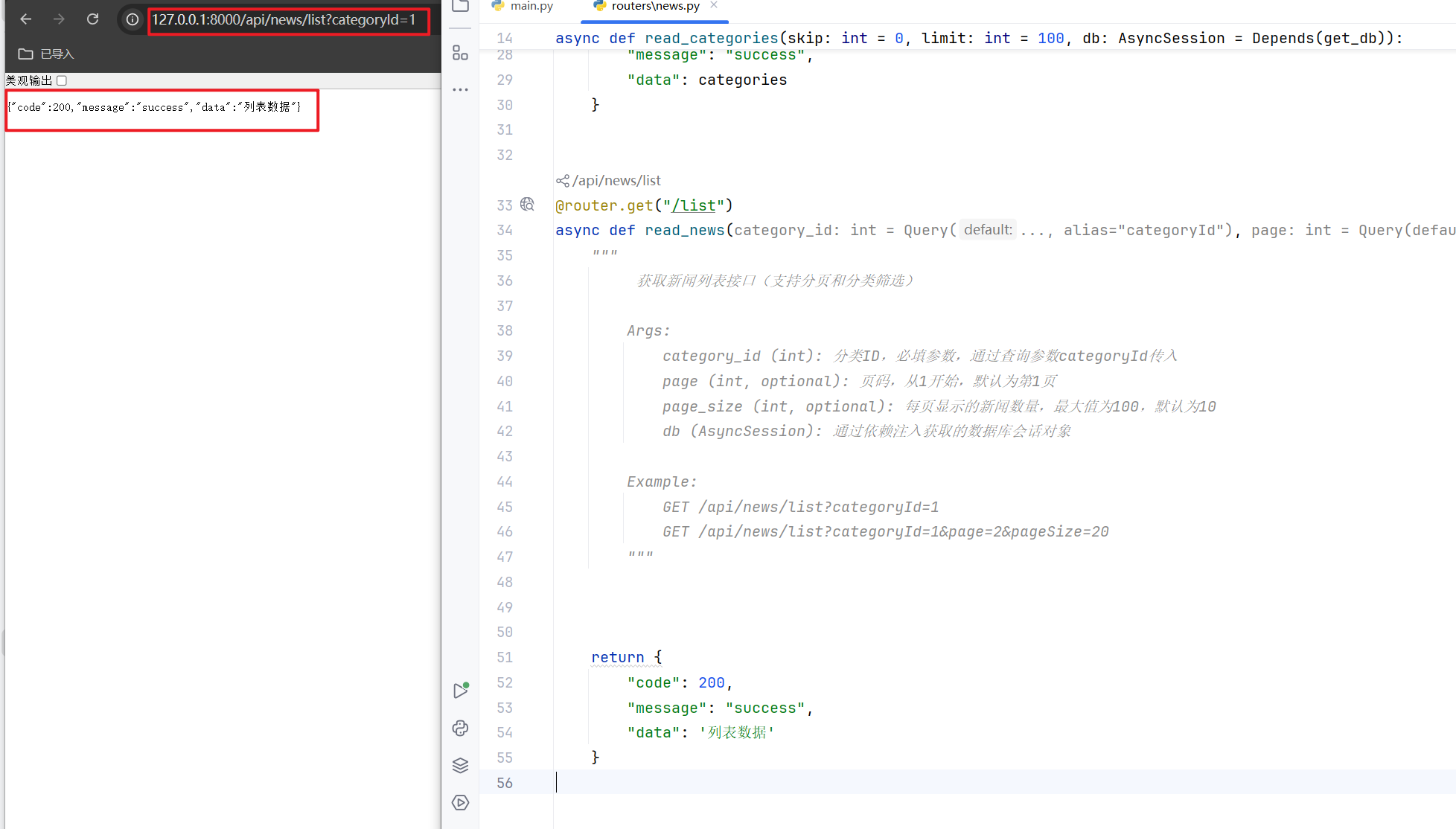
重启FastAPI服务,运行测试,检查定义的路由接口是否能够处理前端发送的请求
III. 定义模型类
定义对应的模型类,方便对应数据库中的数据进行ORM操作
在news.py文件,编写模型类
| from sqlalchemy import String, Integer, DateTime,Index,Text,ForeignKey
from typing import Optional
## ..................
## 其他代码
## ..................
class News(Base):
"""
新闻模型
对应数据库中的 news 表
"""
__tablename__ = 'news'
# 创建索引
__table_args__ = (
Index('fk_news_category_idx', 'category_id'),
Index('idx_publish_time', 'publish_time'),
)
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True, comment="新闻ID")
title: Mapped[str] = mapped_column(String(255), nullable=False, comment="新闻标题")
description: Mapped[Optional[str]] = mapped_column(String(500), comment="新闻简介")
content: Mapped[str] = mapped_column(Text, nullable=False, comment="新闻内容")
image: Mapped[Optional[str]] = mapped_column(String(255), comment="封面图片URL")
author: Mapped[Optional[str]] = mapped_column(String(50), comment="作者")
category_id: Mapped[int] = mapped_column(Integer, ForeignKey('news_category.id'), nullable=False, comment="分类ID")
views: Mapped[int] = mapped_column(Integer, default=0, nullable=False, comment="浏览量")
publish_time: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, comment="发布时间")
created_at: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, comment="创建时间")
updated_at: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, onupdate=datetime.now,
comment="更新时间")
def __repr__(self):
return f"<News(id={self.id}, title='{self.title}', views={self.views})>"
|

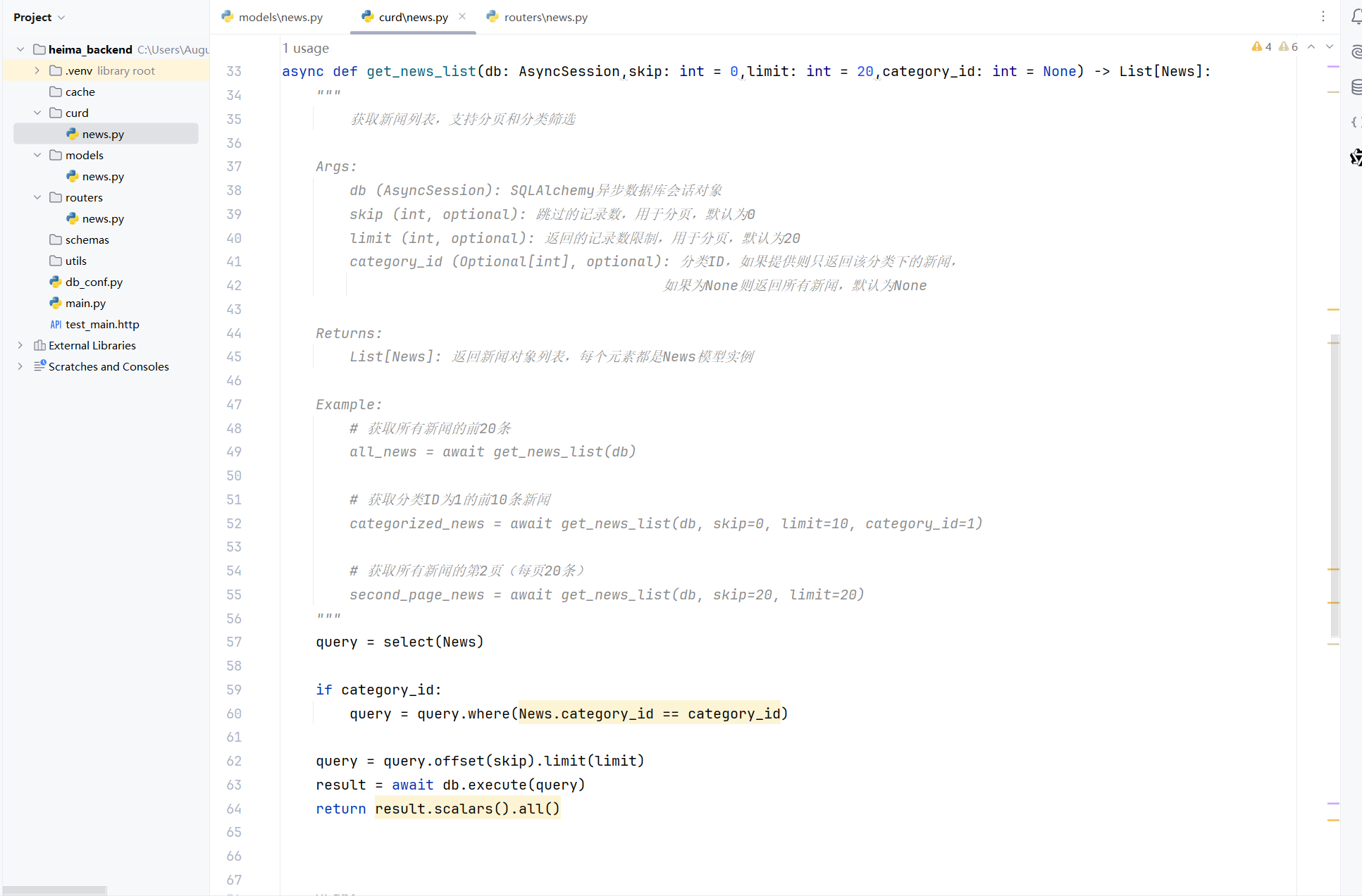
IV. 编写ORM数据操作
在news.py文件,将新闻模块的数据操作按照对应的逻辑编写代码
| from sqlalchemy import select,func
from models.news import Category,News
## ..................
## 其他代码
## ..................
async def get_news_list(db: AsyncSession,skip: int = 0,limit: int = 20,category_id: int = None) -> List[News]:
"""
获取新闻列表,支持分页和分类筛选
Args:
db (AsyncSession): SQLAlchemy异步数据库会话对象
skip (int, optional): 跳过的记录数,用于分页,默认为0
limit (int, optional): 返回的记录数限制,用于分页,默认为20
category_id (Optional[int], optional): 分类ID,如果提供则只返回该分类下的新闻,
如果为None则返回所有新闻,默认为None
Returns:
List[News]: 返回新闻对象列表,每个元素都是News模型实例
Example:
# 获取所有新闻的前20条
all_news = await get_news_list(db)
# 获取分类ID为1的前10条新闻
categorized_news = await get_news_list(db, skip=0, limit=10, category_id=1)
# 获取所有新闻的第2页(每页20条)
second_page_news = await get_news_list(db, skip=20, limit=20)
"""
query = select(News)
if category_id:
query = query.where(News.category_id == category_id)
query = query.offset(skip).limit(limit)
result = await db.execute(query)
return result.scalars().all()
async def get_news_count(db: AsyncSession, category_id: int = None) -> int:
"""
获取新闻总数,可选择性地按分类筛选
Args:
db (AsyncSession): SQLAlchemy异步数据库会话对象
category_id (Optional[int], optional): 分类ID,如果提供则只统计该分类下的新闻数量,
如果为None则统计所有新闻数量,默认为None
Returns:
int: 满足条件的新闻总数
Example:
# 获取所有新闻总数
total_count = await get_news_count(db)
# 获取分类ID为1的新闻数量
category_count = await get_news_count(db, category_id=1)
"""
query = select(func.count(News.id))
if category_id:
query = query.where(News.category_id == category_id)
result = await db.execute(query)
return result.scalar_one()
|
V. 路由中实现数据操作
回到对应的路由中,调用刚才编写好的数据处理函数。
| from curd import news
@router.get("/list")
async def read_news(category_id: int = Query(..., alias="categoryId"), page: int = Query(default=1),page_size: int = Query(default=10, alias="pageSize", le=100),db: AsyncSession = Depends(get_db)):
"""
获取新闻列表接口(支持分页和分类筛选)
Args:
category_id (int): 分类ID,必填参数,通过查询参数categoryId传入
page (int, optional): 页码,从1开始,默认为第1页
page_size (int, optional): 每页显示的新闻数量,最大值为100,默认为10
db (AsyncSession): 通过依赖注入获取的数据库会话对象
Example:
GET /api/news/list?categoryId=1
GET /api/news/list?categoryId=1&page=2&pageSize=20
"""
skip = (page - 1) * page_size
limit = page_size
# 获取新闻列表
news_list = await news.get_news_list(db, skip=skip, limit=limit, category_id=category_id)
# 获取总数
total_count = await news.get_news_count(db, category_id=category_id)
# 计算是否有更多
has_more = (skip + len(news_list)) < total_count
return {
"code": 200,
"message": "success",
"data": {
"list": news_list,
"total": total_count,
"hasMore": has_more
}
}
|
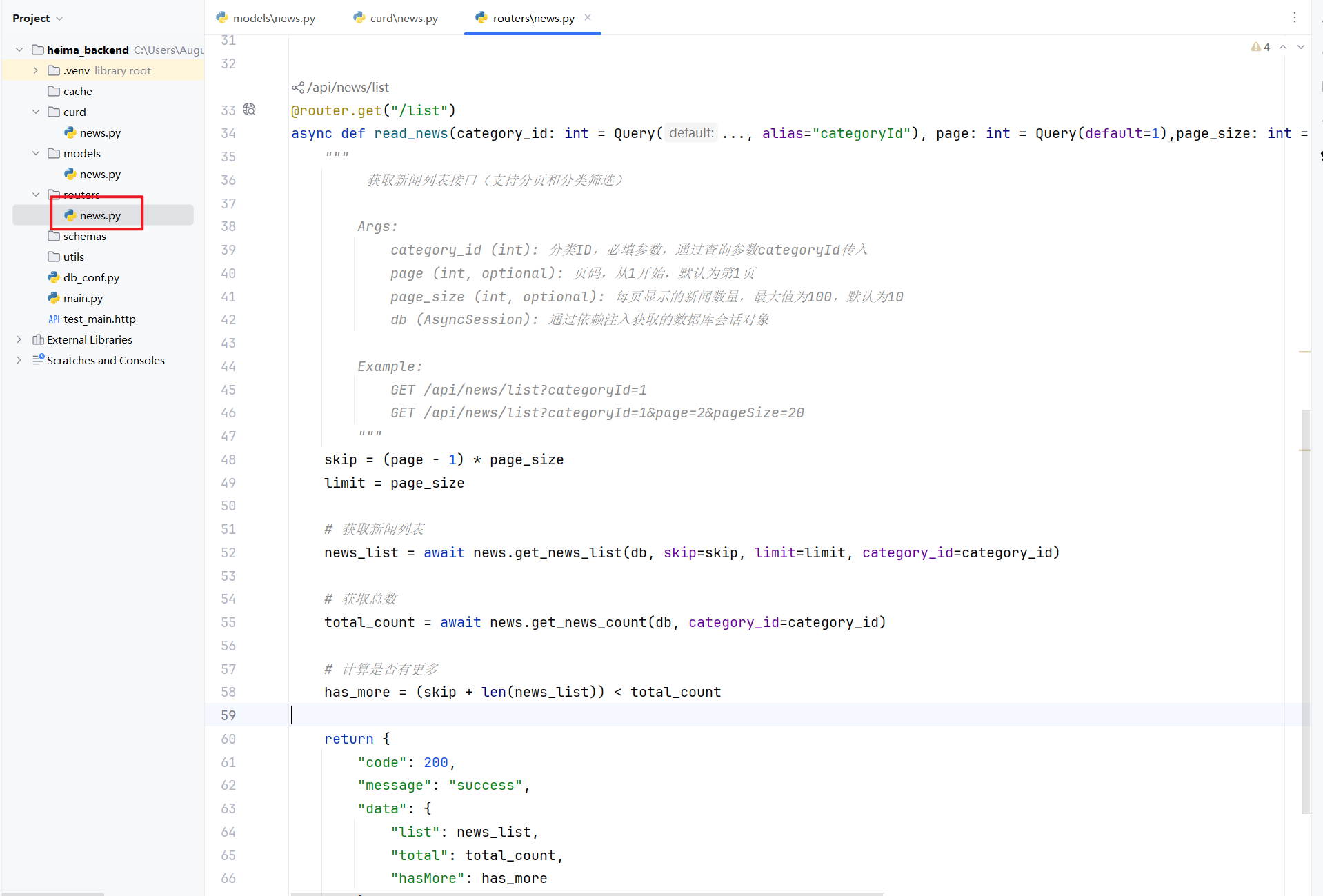
重启FastAPI服务,测试数据是否正常返回
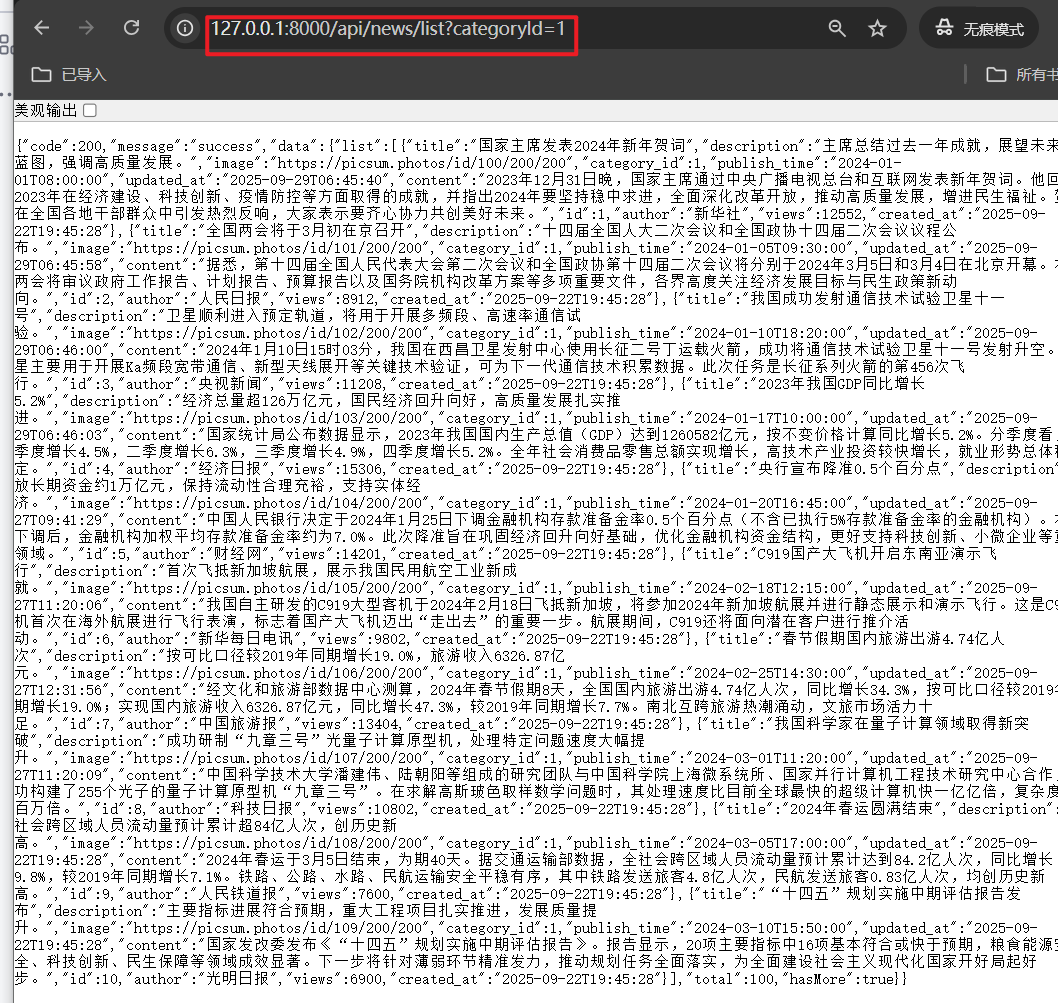
启动前端服务检查数据是否正常加载